age_free_text <- list(
"I go by Alex. 42 years on this planet and counting.",
"Pleased to meet you! I'm Jamal, age 27.",
"They call me Li Wei. Nineteen years young.",
"Fatima here. Just celebrated my 35th birthday last week.",
"The name's Robert - 51 years old and proud of it.",
"Kwame here - just hit the big 5-0 this year."
)Programming with LLMs
Getting Started with LLM APIs in R
R/Pharma 2025
2025-11-03
Providers and Models
- Provider
- company that hosts and serves models
- Model
- a specific LLM with particular capabilities
How are models different?
- Content: How many tokens can you give the model?
- Speed: How many tokens per second?
- Cost: How much does it cost to use the model?
- Intelligence: How smart is the model?
- Capabilities: Vision, reasoning, tools, etc.










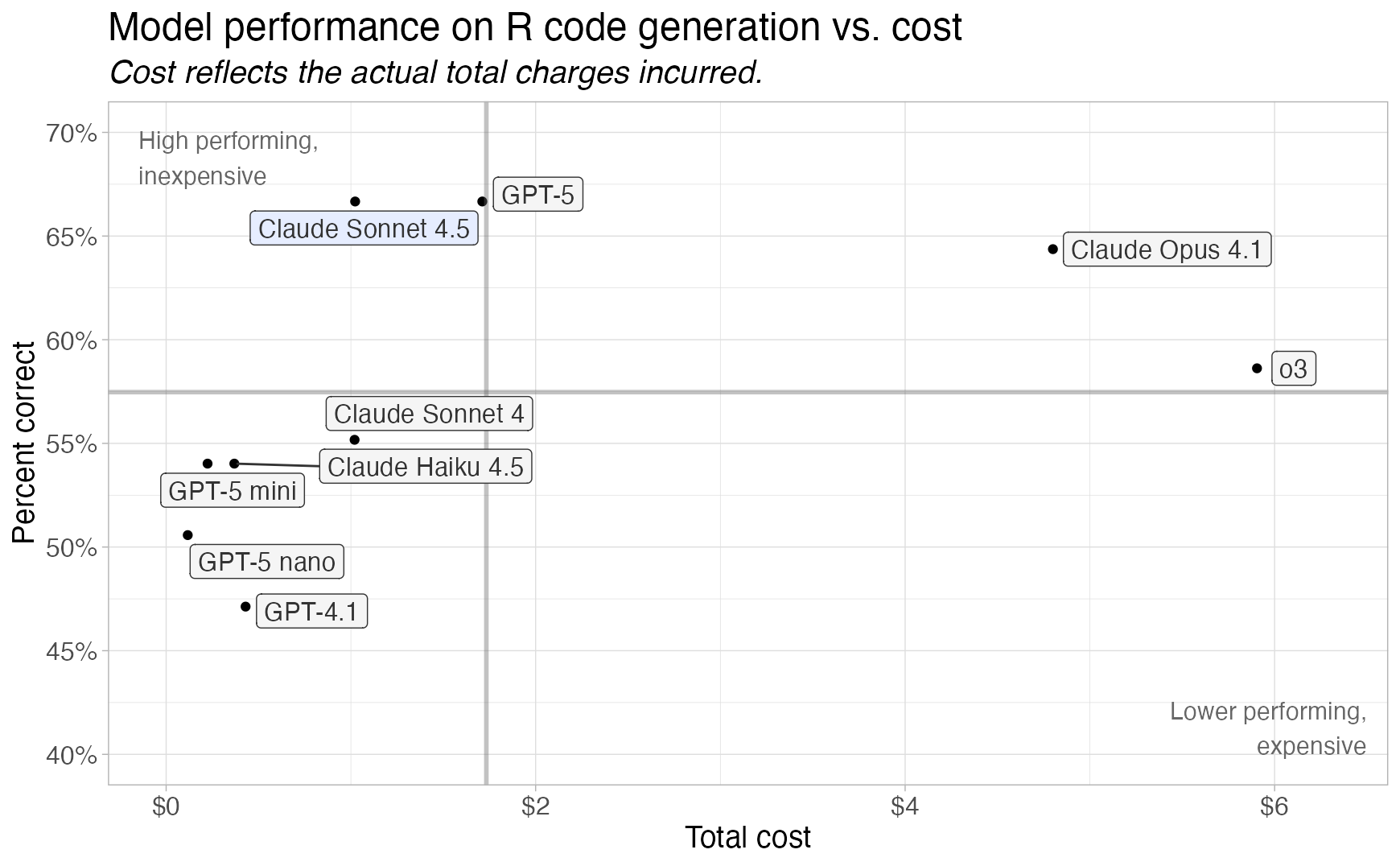
How to choose a model
Generally: just start with a recent frontier model.
- GPT-5
- Claude Sonnet 4.5
- Gemini 2.5 Pro

Providers
chat_openai()chat_anthropic()chat_google_gemini()
Local models
chat_ollama()
Enterprise
chat_aws_bedrock()
Chat in Easy Mode
Chat in Easy Mode
Chat in Easy Mode
Chat in Easy Mode
Your Turn 04_models
04:00
Use
ellmerto list available models from Anthropic and OpenAI.Send the same prompt to different models and compare the responses.
Feel free to change the prompt!
Favorite models for today
- OpenAI
gpt-4.1-nanogpt-5
- Anthropic
claude-sonnet-4-5-20250929claude-3-5-haiku-20241022
How to choose a model

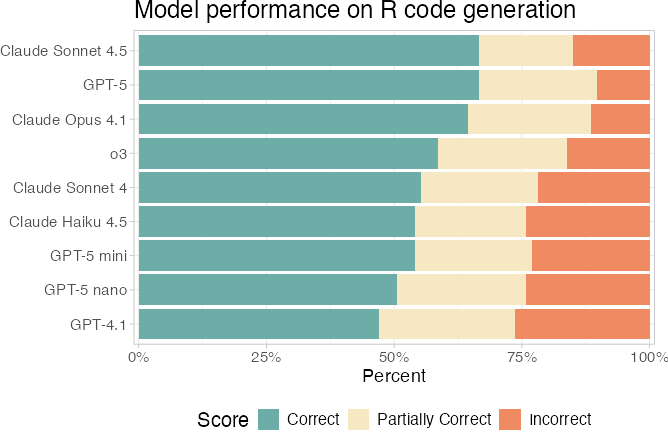
How to choose a model
Multi-modal input
Multi-modal input
A picture is worth a thousand words
Or for an LLM, a picture is roughly 227 words, or 170 tokens.
🌆 content_image_file
🐈 content_image_url
Your Turn 05_vision
I’ve put some images of food in the
data/recipes/imagesfolder.Your job: show the food to the LLM and ask it to write a corresponding recipe.
05:00
📑 content_pdf_file / content_pdf_url
Structured output
How would you extract name and age?
If you wrote R code, it might look like this…
word_to_num <- function(x) {
# normalize
x <- tolower(x)
# direct numbers
if (grepl("\\b\\d+\\b", x)) return(as.integer(regmatches(x, regexpr("\\b\\d+\\b", x))))
# hyphenated like "5-0"
if (grepl("\\b\\d+\\s*-\\s*\\d+\\b", x)) {
parts <- as.integer(unlist(strsplit(regmatches(x, regexpr("\\b\\d+\\s*-\\s*\\d+\\b", x)), "\\s*-\\s*")))
return(10 * parts[1] + parts[2])
}
# simple word numbers
ones <- c(
zero=0, one=1, two=2, three=3, four=4, five=5, six=6, seven=7, eight=8, nine=9,
ten=10, eleven=11, twelve=12, thirteen=13, fourteen=14, fifteen=15, sixteen=16,
seventeen=17, eighteen=18, nineteen=19
)
tens <- c(twenty=20, thirty=30, forty=40, fifty=50, sixty=60, seventy=70, eighty=80, ninety=90)
# e.g., "nineteen"
if (x %in% names(ones)) return(ones[[x]])
# e.g., "thirty five" or "thirty-five"
x2 <- gsub("-", " ", x)
parts <- strsplit(x2, "\\s+")[[1]]
if (length(parts) == 2 && parts[1] %in% names(tens) && parts[2] %in% names(ones)) {
return(tens[[parts[1]]] + ones[[parts[2]]])
}
if (length(parts) == 1 && parts[1] %in% names(tens)) return(tens[[parts[1]]])
return(NA_integer_)
}
# Extract name candidates
extract_name <- function(s) {
# patterns that introduce a name
pats <- c(
"I go by\\s+([A-Z][a-z]+)",
"I'm\\s+([A-Z][a-z]+(?:\\s+[A-Z][a-z]+)?)",
"They call me\\s+([A-Z][a-z]+(?:\\s+[A-Z][a-z]+)?)",
"^([A-Z][a-z]+) here",
"The name's\\s+([A-Z][a-z]+)",
"^([A-Z][a-z]+)\\s" # fallback: leading capital word
)
for (p in pats) {
m <- regexpr(p, s, perl = TRUE)
if (m[1] != -1) {
return(sub(p, "\\1", regmatches(s, m)))
}
}
NA_character_
}
# Extract age phrases and convert to number
extract_age <- function(s) {
# capture common age phrases around a number
m <- regexpr("(\\b\\d+\\b|\\b\\d+\\s*-\\s*\\d+\\b|\\b[Nn][a-z-]+\\b)\\s*(years|year|birthday|young|this)", s, perl = TRUE)
if (m[1] != -1) {
token <- sub("(years|year|birthday|young|this)$", "", trimws(substring(s, m, m + attr(m, "match.length") - 1)))
return(word_to_num(token))
}
# handle pure word-number without trailing keyword (e.g., "Nineteen years young." handled above)
m2 <- regexpr("\\b([A-Z][a-z]+)\\b\\s+years", s, perl = TRUE)
if (m2[1] != -1) {
token <- tolower(sub("\\s+years.*", "", regmatches(s, m2)))
return(word_to_num(token))
}
# handle hyphenated "big 5-0"
m3 <- regexpr("big\\s+(\\d+\\s*-\\s*\\d+)", s, perl = TRUE)
if (m3[1] != -1) {
token <- sub("big\\s+", "", regmatches(s, m3))
return(word_to_num(token))
}
NA_integer_
}If you wrote R code, it might look like this…
# A tibble: 6 × 2
name age
<chr> <int>
1 Alex 42
2 Jamal NA
3 Li Wei NA
4 Fatima NA
5 Robert 51
6 Kwame 5[[1]]
[1] "I go by Alex. 42 years on this planet and counting."
[[2]]
[1] "Pleased to meet you! I'm Jamal, age 27."
[[3]]
[1] "They call me Li Wei. Nineteen years young."
[[4]]
[1] "Fatima here. Just celebrated my 35th birthday last week."
[[5]]
[1] "The name's Robert - 51 years old and proud of it."
[[6]]
[1] "Kwame here - just hit the big 5-0 this year."But if you ask an LLM…
But if you ask an LLM…
Wouldn’t this be nice?
Structured chat output
Structured chat output
Structured chat output
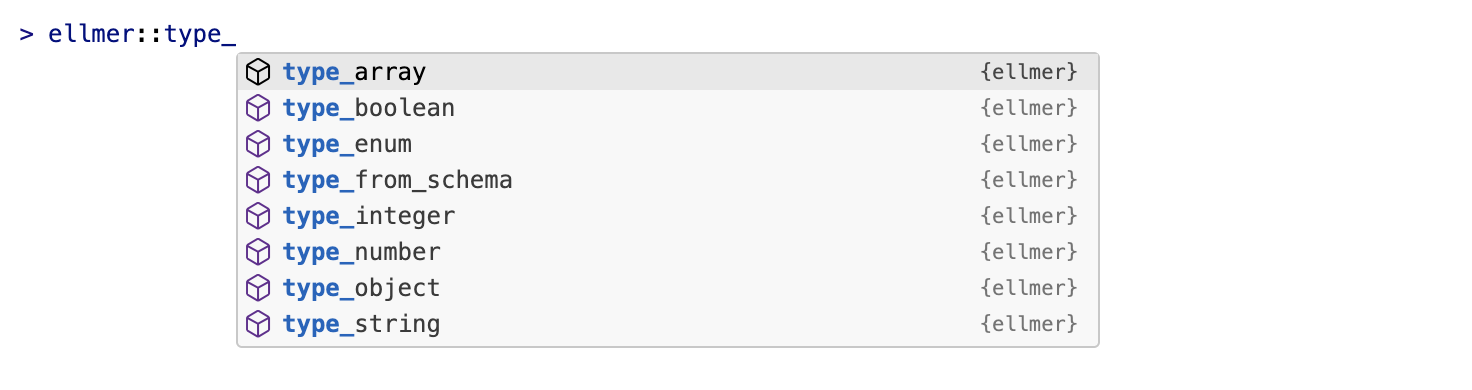
ellmer’s type functions
Your Turn 06_structured-output
data/recipes/txtcontains a set of recipes.Use
ellmer::type_*()to extract structured data from the Cinnamon Peach Oat Waffles recipe (already read in for you).I’ve given you the expected structure, you just need to implement it.
If you have extra time, try it with other recipes in the folder.
07:00